Finding Water From Space
I recently wrote a post about making a data pipeline for satellite images. Following up on what I learned from that project, I decided to put the satellite images into use.
Finding Water
Water is one of the greatest natural resources. Both for consumption and irrigation of crops, but also for real-estate. Example of water being a real-estate asset is for power production with floating solar and offshore wind farms.
For these reasons I chose to make an object detection application using Darknet and the YOLO algorithm to detect lakes and rivers in satellite images.
You Only Look Once
The YOLO algorithm is well suited for fast object detection, and can even be applied on video for real-time use. At a later point, it would be interesting to apply it on a satellite video stream 🤓
I used YOLOv4. The git repo has link to Colab notebooks a video tutorials. You might have to build openCV from source and do a bit of configuration to make it work on your pc. All in the day of a ML engineer.
Creating the Dataset
YOLO requires that the dataset has a number of pictures with matching text files that describe where in the pictures a given object is. You can use preexisting datasets like COCO to get started quickly. But if you want to detect objects that is not in a preexisting dataset you will have to create a dataset yourself.
Creating RGB images
First of all we need to have pictures. Instead of downloading pictures from a search engine I piggy backed of my previous work with the bigearth.net dataset and created an Apache Beam pipeline to create RGB images.
The pipeline can be summed up as:
Annotating the Images
As mentioned before, we need to create text files that tell where the desired object are in the images. There are several different tool you can use. I went with makesense.ai because it is easy to use and supports the YOLO format, so no conversion is needed.
Annotating images manually is a bit tedious so I only used 500 images. Some of those was of poor quality so I discarded them and ended up with 491 text files for my dataset.
Training the Model
Once darknet was built and I created my dataset the training step was straight forward.
Again, you might have to change some parameters in the Makefile and/or .cfg file to make it work with our setup and dataset.
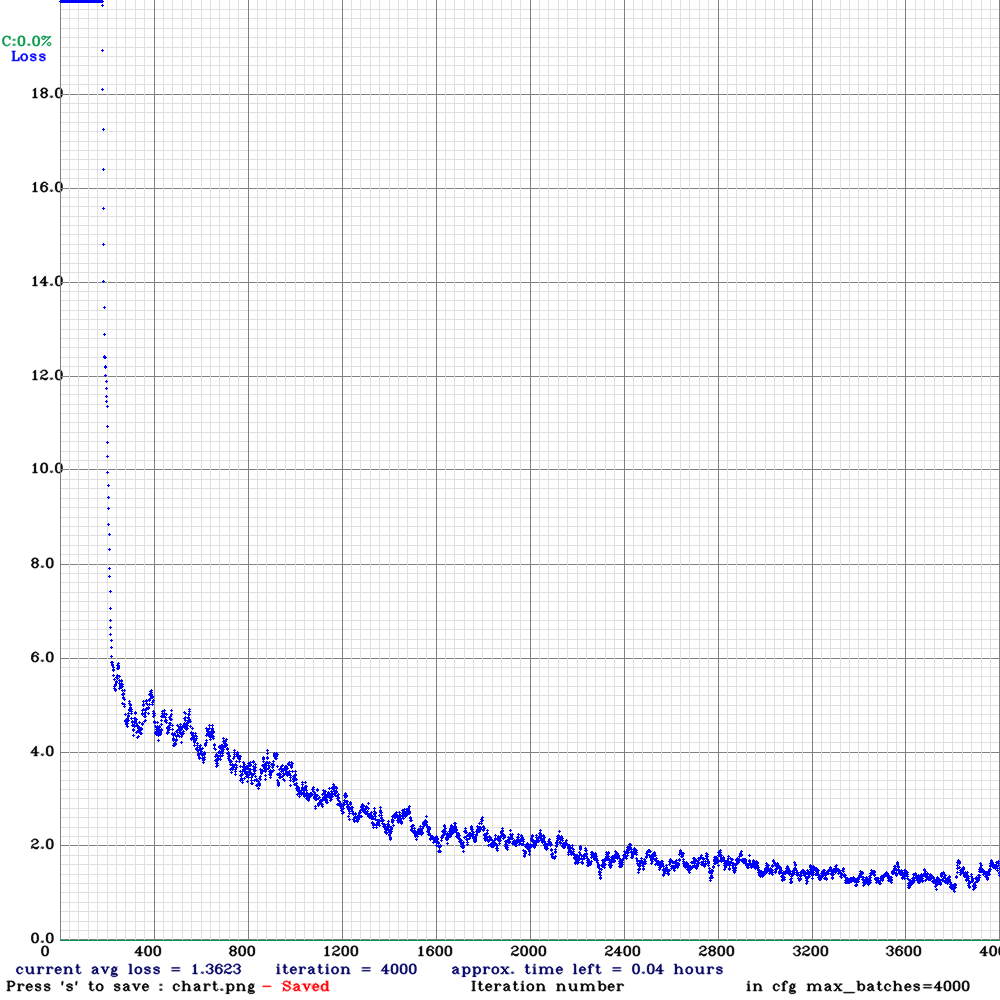
After reading some blog posts and watching some videos I suspected that the model would converge at about 4000 batches so I used that for `max_batches` in my .cfg file.
I set the width and height to 128 (needs to be a multiple of 32) since the jpgs I created all are 120x120.
The first few lines of the .cfg looks like this:
[net]
batch=64
subdivisions=8
# Training
#width=512
#height=512
width=128
height=128
channels=3
momentum=0.949
decay=0.0005
angle=0
saturation = 1.5
exposure = 1.5
hue=.1
learning_rate=0.0013
burn_in=1000
max_batches = 4000
policy=steps
steps=3200,3600
scales=.1,.1
Starting the training is as simple as running
./darknet <path/to/your.data> <path/to/your.cfg> <path/to/weights>
In my case:
./darknet detector train ~/ai/water-yolo/water.data cfg/yolov4-2-classes.cfg yolov4.conv.137
Depending on the system you are training on and the size of the dataset, the training will take from a few minutes to several hours.
With my old-ish pc and a GeForce GTX 1660 SUPER GPU it took about 2 hours to train for 4000 epochs.
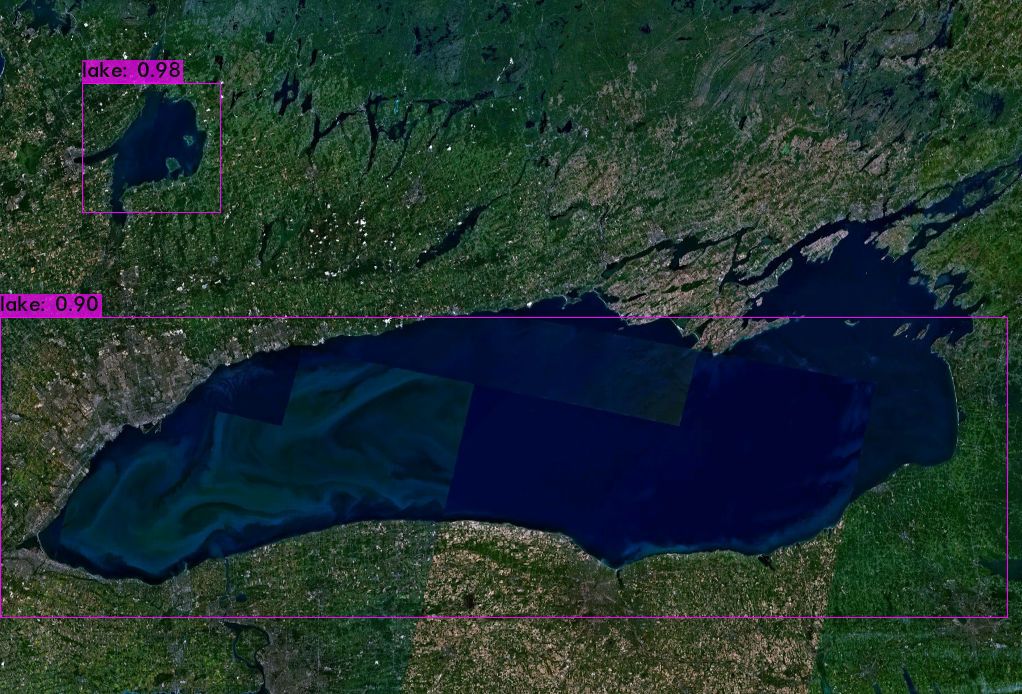
The Result
To do a simple test of the trained model, I downloaded a picture from NASA that contained a lake. Here's the prediction the model made:
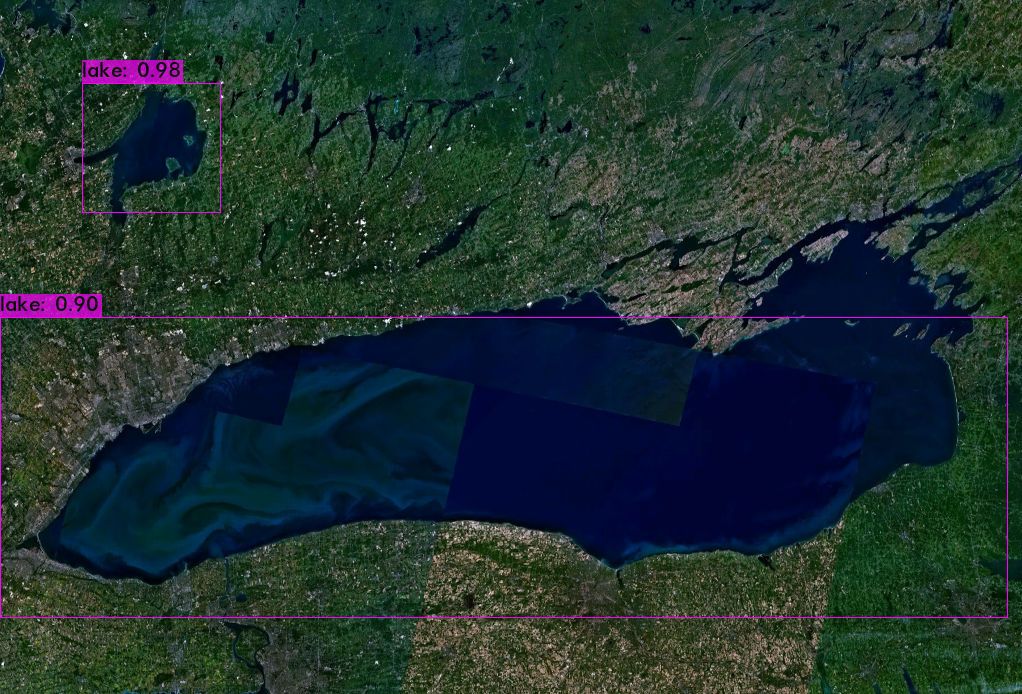
Not perfect, but not bad for such a limited dataset and amount of training.
Thanks for reading
I tried to keep this short since there a tons of articles on YOLO and satellite imagery. Hopefully this had some value for you.